研究S5对称群的circuit
研究S5对称群的circuit
Justin Wu研究S5对称群的circuit
这篇文章是在我研究circuits的过程中,对实验的进一步理解和总结。我们得到了以下结论:
在同一个 (S_5) 群乘法任务上,模型可以学到多个不同的表示论 circuit;optimizer 会改变这些 circuit 出现的概率和形成路径,但它不是一个确定的 optimizer-to-circuit 映射。
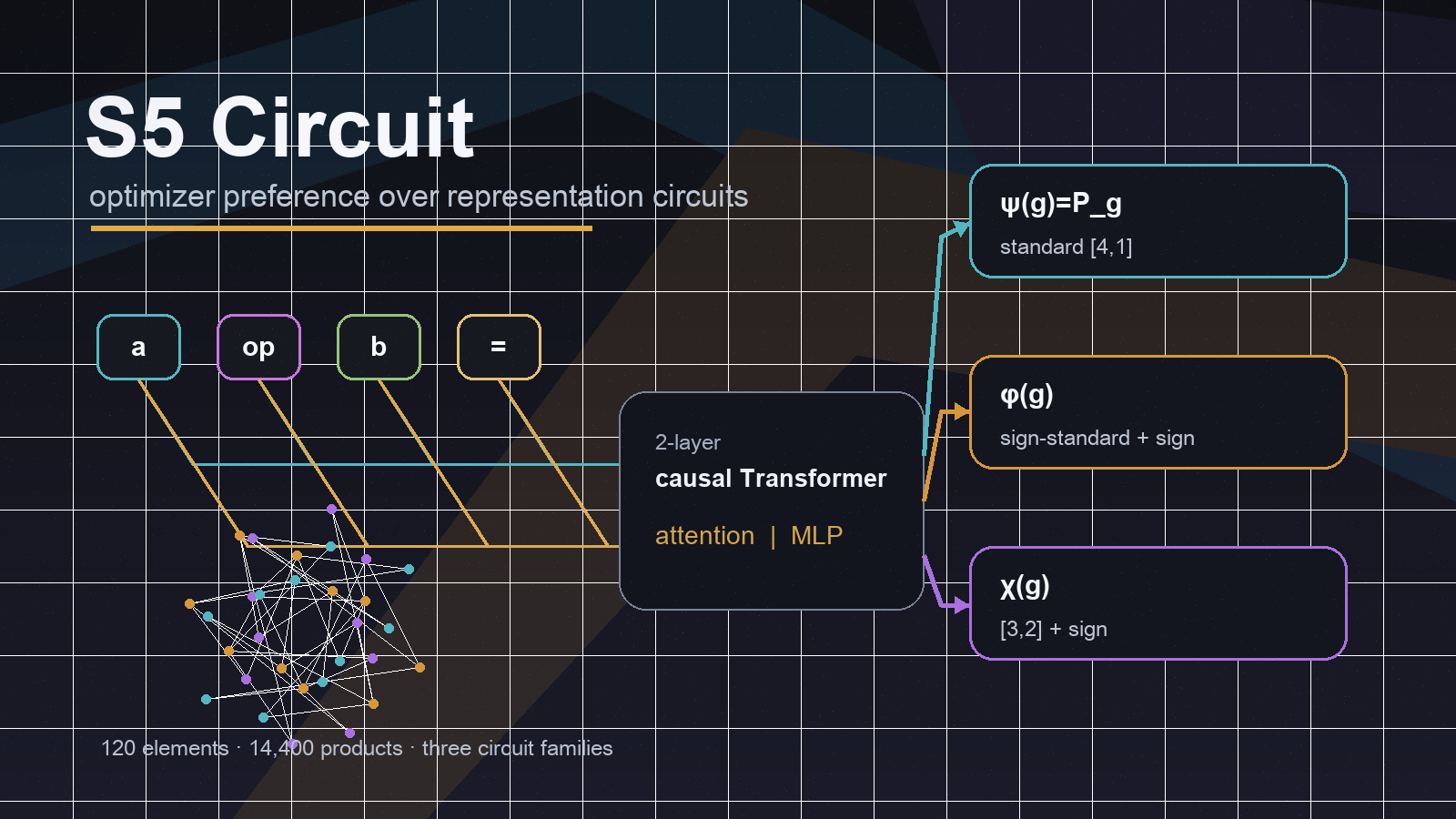
任务:让 Transformer 学 S5 乘法
任务本身很小。令 (G=S_5),也就是五个点上的对称群。每个元素都是一个置换。模型输入两个群元素 (a,b),输出它们的复合:
在代码里,输入序列写成:
[left_element, op_token, right_element, equals_token]
模型在最后一个 token 位置输出 120 类 logits。因为 (S_5) 有 120 个元素,所以完整乘法表有:
个输入 pair。主实验使用 train_frac=0.4,也就是 5760 个训练 pair 和 8640 个测试 pair。
模型是 2 层 causal Transformer,d_model=128,n_heads=4。这个模型对任务来说是过参数化的:它不只有一种方式可以把任务做对。这正是实验的关键,因为我想问的是:
当多个模型都达到近乎完美测试准确率时,它们内部是否一定学到了同一个算法?
答案是否定的,他们分化出了不同的circuits。
为什么 S5 是一个好 toy model
我最开始做 modular addition 时,不同 optimizer 最终大多还是走向同一个高层 Fourier/relation circuit,只是在速度、低层几何和 component dependence 上不同(比如模加法)。那样的任务不足以强烈地区分“不同 optimizer 是否会导致不同最终算法”。而(S_5) 更适合这个问题,因为它是非交换群。一般情况下:
这迫使模型必须区分左操作数和右操作数,也迫使 circuit 不能只是普通的向量加法。更重要的是,(S_5) 的表示论结构足够丰富:它不是只有一种自然坐标。一个 group element 可以被编码到不同 irreducible representation sector 里,而这些 sector 之间不是简单线性换基。
这给我们提供了一个很干净的判断标准:如果两个模型的 product code 落在不同不可约表示成分里,那它们就不是“同一个 circuit 换了坐标系”,而是真的使用了不同的内部算法。
三类 product representation
现在的核心发现是:成熟模型至少出现了三类 product representation circuit。
第一类是自然置换表示。我记作:
其中 (P_g) 是 (g) 对应的 (5\times5) permutation matrix。它展开后是 25 维,但由于每行每列只有一个 1,实际 affine rank 是 17,中心化后 rank 是 16。这对应自然置换表示中的 trivial 成分加 standard 成分;去掉均值后主要是:
1 | standard_[4,1] |
这一类 representation 很直观。它记录的是“每个位置 (i) 被置换送到哪里”。如果要计算 (ab),自然公式是:
也就是先由 (b) 把 (i) 送到 (j),再由 (a) 把 (j) 送到 (k)。
第二类是 sign-twisted standard 加 sign。我记作:
它是 17 维:16 维来自 sign-standard 的矩阵系数,1 维来自 sign。它位于:
1 | sign_standard_[2,1,1,1] + sign_[1^5] |
这个表示和自然置换表示维数接近,但不是同一个东西。用 80 个 group elements 拟合 (\psi\to\phi),再在 40 个 heldout elements 上测试,nearest accuracy 是 0;反向也一样失败。也就是说,它们不能通过一个线性换基互相变成对方。
第三类是在 SGD seed2 里偶然发现的。最开始这个 checkpoint 看起来像一个“未知 circuit”:它 test accuracy 是 1.0,但既不对齐 (\psi),也不对齐 (\phi)。后来我做了全 (S_5) irrep projector scan,发现它主要落在:
1 | partition_[3,2] + sign_[1^5] |
更具体地,可以写成:
这里 (\rho_{[3,2]}) 是 (S_5) 的 5 维不可约表示,它的 matrix coefficients 给出 25 维 product code。这解释了为什么原先只看 17 维 (\psi/\phi) codebook 会漏掉它。
不是“都用了群表示所以都一样”
这里有一个容易误解的地方:(\psi,\phi,\chi) 都是群表示或群表示的矩阵系数,那么它们是不是本质一样?
不是。
有限群的不同不可约表示有点像 Fourier analysis 里的不同频率通道。Schur orthogonality 告诉我们,不同 irrep 的 matrix coefficients 在群函数空间里是正交的。这里的差异不是“同一个向量空间旋转一下”,而是模型选择了不同表示论 sector。
可以粗略记成:
1 | psi: centered natural permutation -> standard_[4,1] |
所以本文真正想说的不是“一个模型用了表示论,另一个模型没有”。更准确地说:
这些模型都学到了可泛化的表示论算法,但 optimizer 和训练轨迹会偏向不同的 irreducible representation sector,并把 product compression 放在不同模块中完成。
AdamW:稳定的 phi-MLP product writer
AdamW 是目前最稳定的结论。三个 seed 都收敛到 (\phi)-MLP product writer。
它的 circuit 可以简写成:
1 | layer1 MLP input: |
也就是:
旧版本文章里已经写过这个机制,但现在可以把它放在更清楚的表示论背景下理解。AdamW 的关键不是“MLP 做了查表”,而是 MLP 写出了位于 sign-standard + sign sector 的 product code。
这个 product code 不是任意 label。它在 heldout group elements 上可以和 (\phi(g)) 双向读回;替换中间 operand code 会把输出按群乘法规则 steering 到新 product;恢复 top interaction neurons 可以恢复输出,而只保留 additive part 时接近 chance。
一个特别关键的定位结果是:在 AdamW 中,product signal 不是早就在 MLP input 处出现。MLP input 主要携带左右 operand:
1 | left probe ≈ 1.0 |
真正的 product 在 GELU activation 后出现,然后由 MLP output 写成 (\phi(ab))。这就是为什么我把它叫做 MLP product writer。
Adam+L2 与常见 SGD:psi attention/residual circuit
Adam+L2 和 SGD momentum 的常见成熟 seed 更像另一类 circuit。它们不是在 layer1 MLP output 处写出 (\phi(ab)),而是在 layer1 attention/residual path 中形成自然置换表示:
这类 circuit 更像 coordinate routing。想象 product matrix 的一个 entry:
attention 权重本身不是最终 product code,它更像 gate,选择中间路径 ((i,j,k))。右 token 的 value 在被 final-query attention gating 后变得 product-like;最后 attention contribution 和 residual 合起来,使 (P_{ab}) 可读。
所以它可以简写成:
1 | operand image coordinates |
这和 AdamW 的 MLP (\phi) writer 不是同一个 circuit。Adam+L2/SGD 常见 seed 的 product information 主要在 layer1_attn_all 或 layer1_post_attn 中形成;layer1_mlp_out 的 product patching 基本不能恢复答案。相反,AdamW 的 layer1_mlp_out 本身就足以强制目标 product。
换句话说:
1 | AdamW: |
SGD seed2:第三类 [3,2]+sign circuit
最新进展里最重要的一点,是 SGD seed2。
如果只看 seed0/seed1,很容易写出一个过强结论:“SGD 偏向 (\psi)-attention circuit”。但 seed2 达到 test accuracy 1.0 后,并不对齐 (\psi) 或 (\phi)。这迫使我做了全 (S_5) irrep projector scan。
结果显示,它的 product code 主要落在 [3,2] + sign:
1 | final_hidden: |
这说明它不是 AdamW 式 MLP writer,也不是常见 SGD seed 的 (\psi)-permutation-image circuit。它是第三类 attention/residual representation circuit。
更细的 head-level 分析显示,pre_layer1_resid 已经带有弱 [3,2]+sign product geometry;layer1 attention 写入一个接近 [3,2] 的修正项;二者相加后,在 layer1_post_attn 形成完整 product code。单个 head 通常不是完整 product code,而是把 [3,2] matrix-coefficient code 分布到多个 attention 写入方向里。
我现在对它的理解是:
1 | pre-layer1 residual |
其中:
继续训练也支持这个判断。SGD seed2 从 10k 继续到 60k、100k 后,没有转向 AdamW 式 MLP product writer。相反,final_hidden 的 [3,2] share 从 0.6641 上升到约 0.783,layer1_mlp_out 的 product cluster 一直在 chance 附近。这说明 [3,2]+sign 不是一个短暂过渡态,而是稳定下来的第三类 circuit。
实验结果
仅看成熟 checkpoint 还不够,因为可能有人会说:最后的表示不同只是读出层或坐标选择的偶然结果。为此我从零重训 AdamW、Muon、Adam+L2,并在训练中途做 representation-basis 读数。
全部的circuit分析结果:
1 | AdamW: |
这说明差异不是成熟后才被读出来的表层几何,而是 product code 形成路径本身的分岔。AdamW/Muon 走向 MLP (\phi) path,Adam+L2 走向 attention (\psi) path。
Muon 在这里尤其有趣。它在某个 run 中 test accuracy 还很低时,mlp_phi 已经达到 1.0;后续泛化提升更像 readout/cleanup。这说明 representation circuit 的形成和最终 test accuracy 的跃迁不是完全同一件事。
Seed sweep:结论要写成 preference
多 seed 结果让结论变得更科学,也更克制。
目前成熟模型的 circuit call 是:
1 | AdamW: |
这张表改变了我对整个项目的假设。现在不能写成:
1 | AdamW -> phi |
因为 SGD seed2 已经给出反例,Muon seed1 也显示了 seed sensitivity。更合适的表述是:
1 | AdamW **strongly** prefers phi-MLP writer. |
也就是说,optimizer 改变的是 circuit formation 的分布,而不是单独决定最终 circuit。
相关文献
我做完前一轮实验后,发现了 Chughtai, Chan, and Nanda 的论文 A Toy Model of Universality: Reverse Engineering How Networks Learn Group Operations。这篇论文研究小神经网络如何学习有限群 composition,并用 representation theory 描述 group operation circuit。
这篇论文让我重新组织了自己的结果。
它给出的背景是:有限群运算任务上的模型确实可能学习表示论算法,而不是简单记忆乘法表;但这种 universality 不是强 universality。模型可能都使用 group representation machinery,却选择不同 representation、不同具体 circuit。
我的实验接在这个问题上继续往前推了一步:如果固定同一个 (S_5) 任务和同一个 Transformer 架构,只改变 optimizer 与训练轨迹,会不会改变模型最终落到哪个 representation circuit?
现在的答案是:会,但不是确定映射。
所以我对自己工作的定位是:
- 复现并验证有限群运算任务中的 representation circuit 多样性。
- 把比较维度从“不同模型/不同 seed 是否 universal”推进到“optimizer 是否改变 circuit 分布”。
- 在 (S_5) 上定位三类可泛化 circuit:(\psi)、(\phi)、([3,2]+sign)。
- 给出一个更谨慎的正例:optimizer affects circuit formation, but not deterministically.
结论
第一,行为等价不等于机制等价。所有这些模型都能把 (S_5) 乘法做到接近完美,但内部算法不同。
第二,这些差异不是简单换基。自然置换表示、sign-twisted standard 表示、[3,2]+sign 表示属于不同 irrep sector。跨 sector 的 heldout affine transfer 失败,说明它们不是同一个 code 的旋转。
第三,product compression 的模块位置也不同。AdamW 的关键计算发生在 layer1 MLP 的 GELU interaction 中;Adam+L2/常见 SGD 主要发生在 layer1 attention/residual 的 coordinate routing 中;SGD seed2 则是 residual 加 [3,2]-directed attention update。
第四,optimizer 的确会影响 circuit formation。AdamW 对 (\phi)-MLP writer 的偏好很稳定;Adam+L2 和 SGD 更常出现 attention/residual circuit;Muon 有 seed sensitivity。
第五,当前实验仍然只是一个强机制案例,不是完整统计定律。seed 数量还少,任务也只是 (S_5)。下一步应该扩大 seed sweep,测试更多非交换群,并把 causal intervention 汇总成 paper-level main table。
如果用一句话总结现在的版本:
同一个 (S_5) 群乘法函数,可以由多个不同的表示论 circuit 实现;optimizer 改变模型落入这些 circuit 的概率分布,而不是只改变训练速度。
我觉得这比最初那个“AdamW/Muon vs SGD/RMSprop”的二分故事更真实。它也更接近 mechanistic interpretability 里真正困难的部分:模型不是只有一种正确算法。即使在一个小到可以完整枚举的任务上,训练动力学也会把模型送入不同的内部世界。