
Modelmid
This was my midterm project for Mathematical Modeling. I used mathematical-solution attribution as a modeling problem: given a written solution, can I infer whether it came from a human student or from a specific LLM?
I keep the report, data-processing scripts, classifier experiments, and later extensions in GitHub / wjjpku/Modelmid.
What I studied
The original midterm version focused on human writing plus four LLM sources: DeepSeek, Kimi, GLM, and Qwen. Later, I extended the public version with GPT-4.1-mini related generation and adversarial experiments. I do not treat every later figure as part of the original midterm submission; I treat the repository as a course project that kept growing after the deadline.
The point was not ordinary topic classification. The same or similar math problems were answered by different sources, so the detector had to look for writing and formatting fingerprints rather than problem content alone.
I focused on signals such as:
- paragraph count and paragraph length
- line breaks and step formatting
- inline and display LaTeX usage
- logical connectors and proof-transition words
- TF-IDF phrase patterns
- source-specific habits in mathematical explanation

My workflow
- Build paired mathematical-solution datasets across sources.
- Extract lexical, structural, LaTeX, and proof-style features.
- Train traditional machine-learning classifiers and neural baselines.
- Evaluate in-distribution performance, cross-domain generalization, and adversarial rewriting.
- Use feature analysis to understand what the detector is actually relying on.
Models I compared
I compared two families of detectors.
The first family used feature engineering: TF-IDF plus custom structural features, then tree-based models or similar classifiers. This was easier to inspect because I could see whether the model cared about paragraph structure, LaTeX packaging, proof rhythm, or phrase choice.
The second family used end-to-end neural models, including DistilBERT in the expanded experiments. These could be stronger in distribution, but they were also harder to explain. I cared about that tradeoff more than about a single leaderboard number.
How I separate the versions
I now think about the project in two layers.
The midterm layer is the submitted assignment: feature extraction, source classification, cross-domain generalization, and anti-detection analysis on the original source set.
The expanded repository layer adds GPT-4.1-mini generation, stealth-generation scripts, six-source reports, updated figures, and adversarial experiment summaries. I keep that distinction because otherwise the project sounds cleaner than it really was.
The adversarial lesson
The adversarial part became the most interesting lesson. Once I exposed the detector’s feature preferences, a generator could be guided to change its paragraphing, formula packaging, and proof style. Data-driven prompt feedback can weaken a detector surprisingly quickly.
This makes the project more honest than a classifier demo: interpretability helps explain a model, but it also creates an attack surface.
Figures
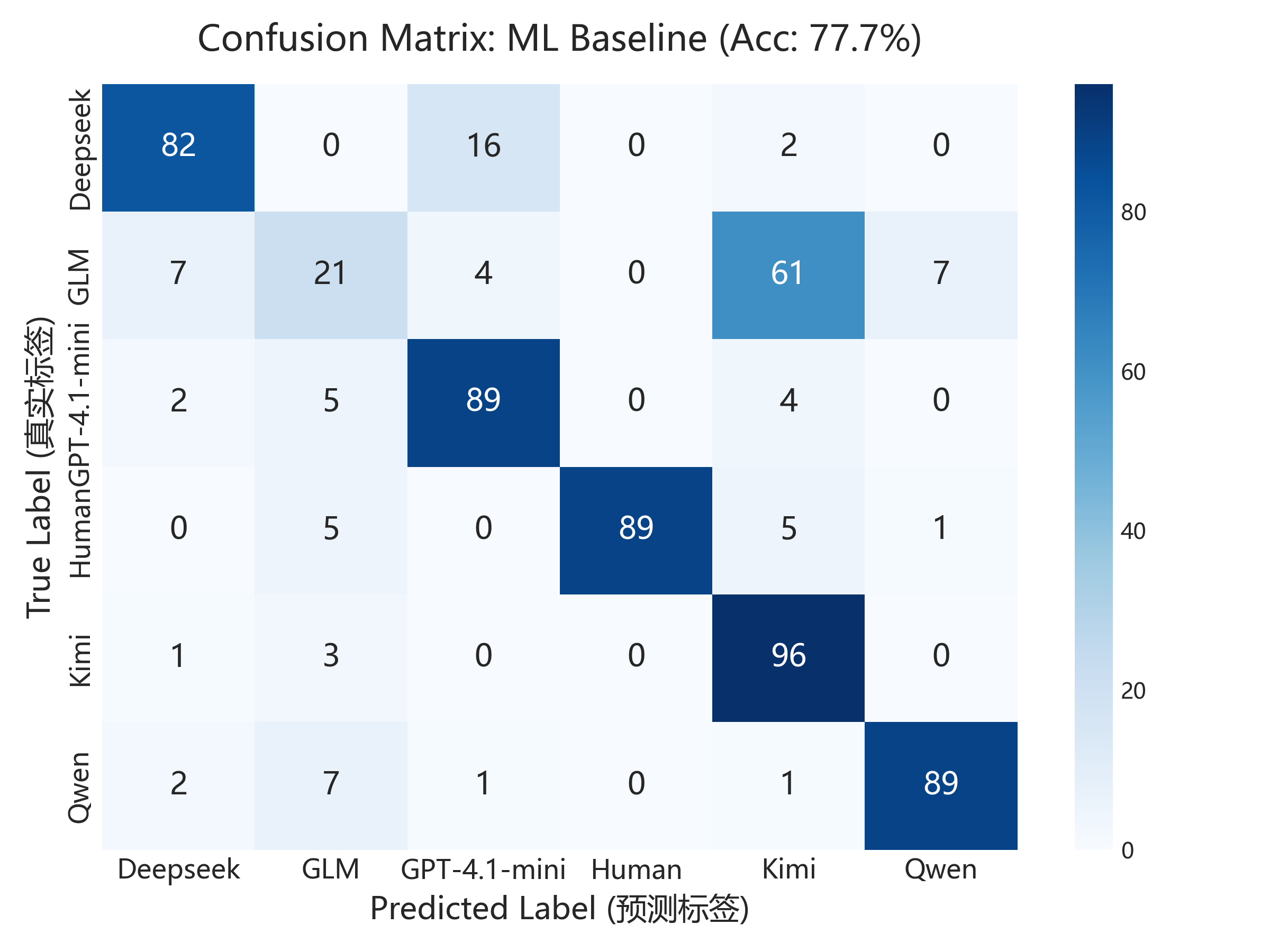
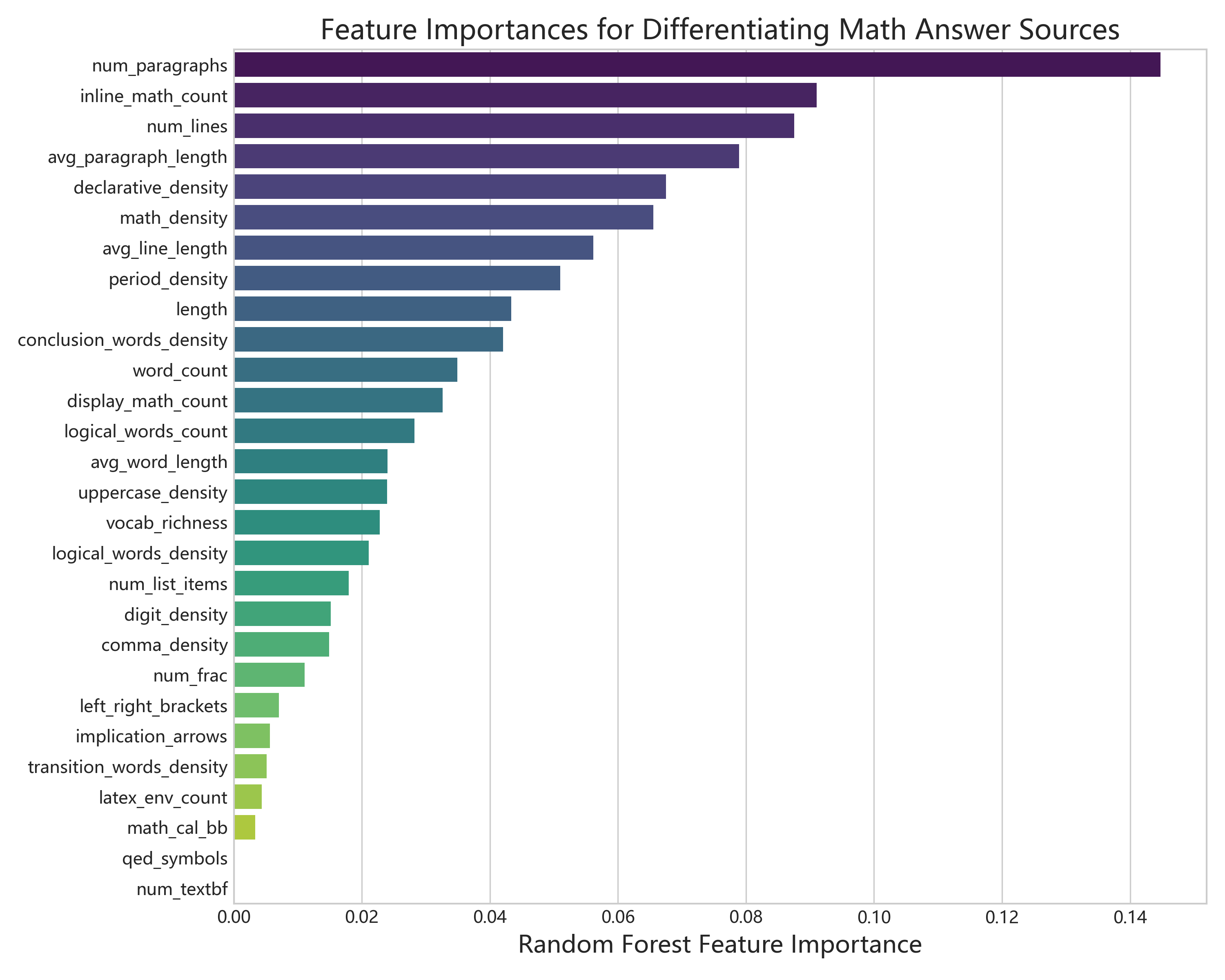
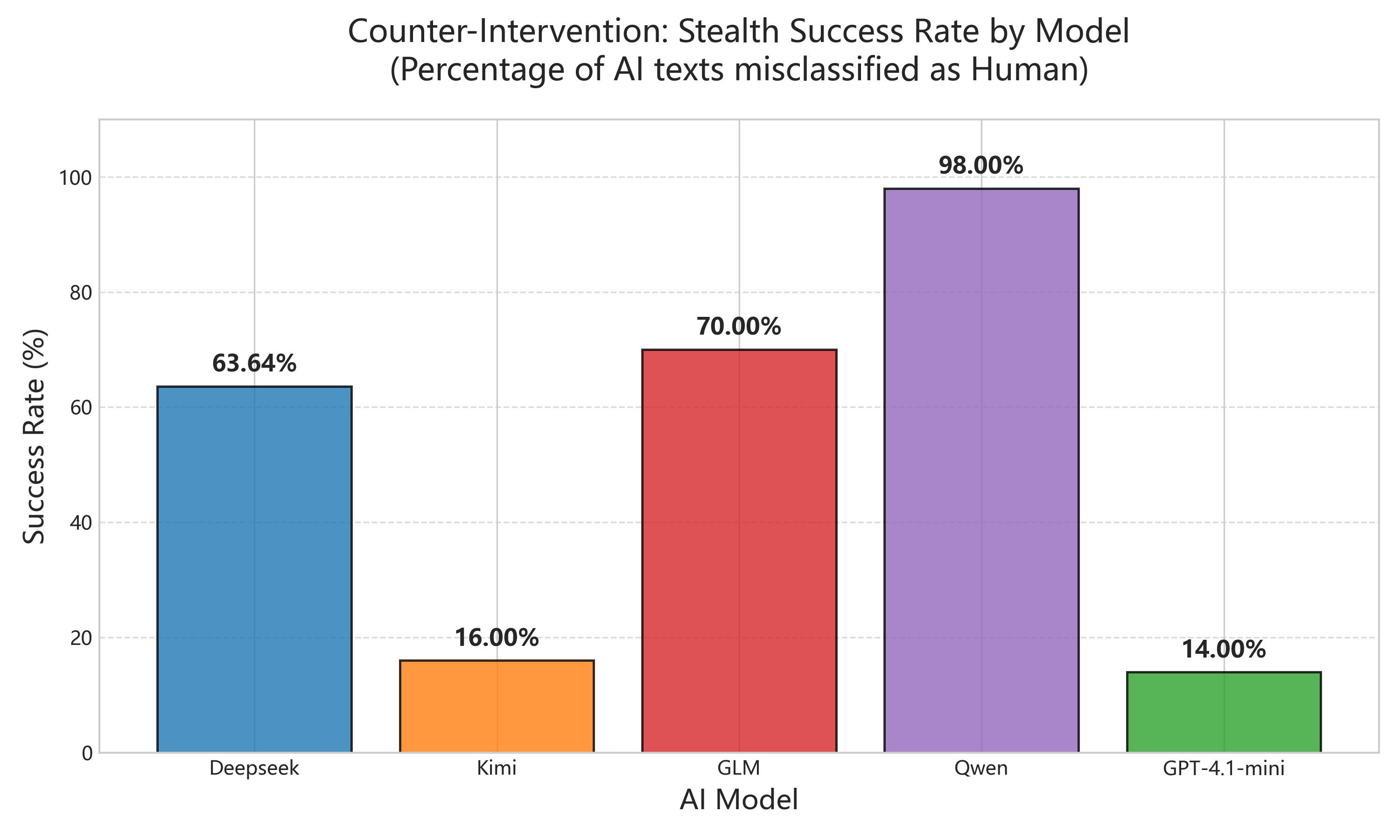
What I Learned
The project taught me to treat detection claims carefully. High in-distribution performance is not the same as robust understanding. A detector can learn real style signals, but those same signals can be manipulated once they are known.
