- 数学文本不是普通自然语言,公式和推导结构本身就是风格信号。
- 对抗实验能反过来提示:哪些“模型味”最容易被检测出来。
- 这个方向适合继续扩展到更多模型、更多学科和更细粒度的写作习惯分析。
Modelmid
Modelmid 研究数学解答文本的来源识别:人类、DeepSeek、Kimi、GLM、Qwen 等不同来源在公式密度、逻辑连接、段落形态和证明语气上会留下可学习的风格痕迹。
项目概览
Modelmid 研究“数学解答是谁写的”。项目以 Human、DeepSeek、Kimi、GLM、Qwen 等来源为主线,提取数学推导文本中的词频、结构、LaTeX、逻辑连接和段落风格等特征,训练分类器判断文本来源。
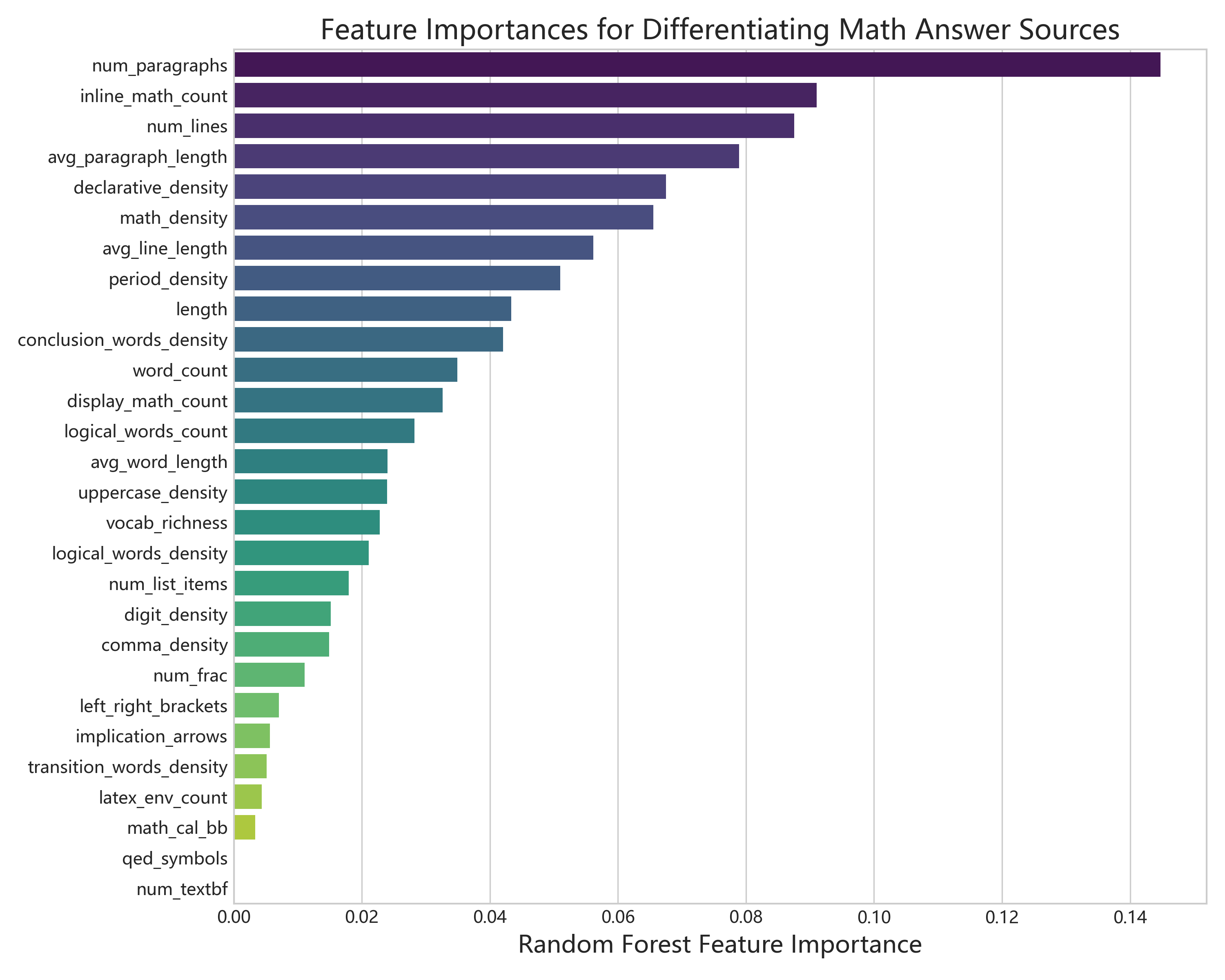
它不是简单地做通用文本分类,而是把数学文本的独特写作痕迹纳入特征:公式数量、行内数学密度、证明语气、逻辑词分布、段落长度等都会影响模型判断。
工作流
项目流程
数据构建
配对数学题目和多来源解答,形成用于训练、泛化测试和对抗实验的数据集。
特征提取
提取 TF-IDF、LaTeX 结构、逻辑连接词、段落形态等特征。
模型训练
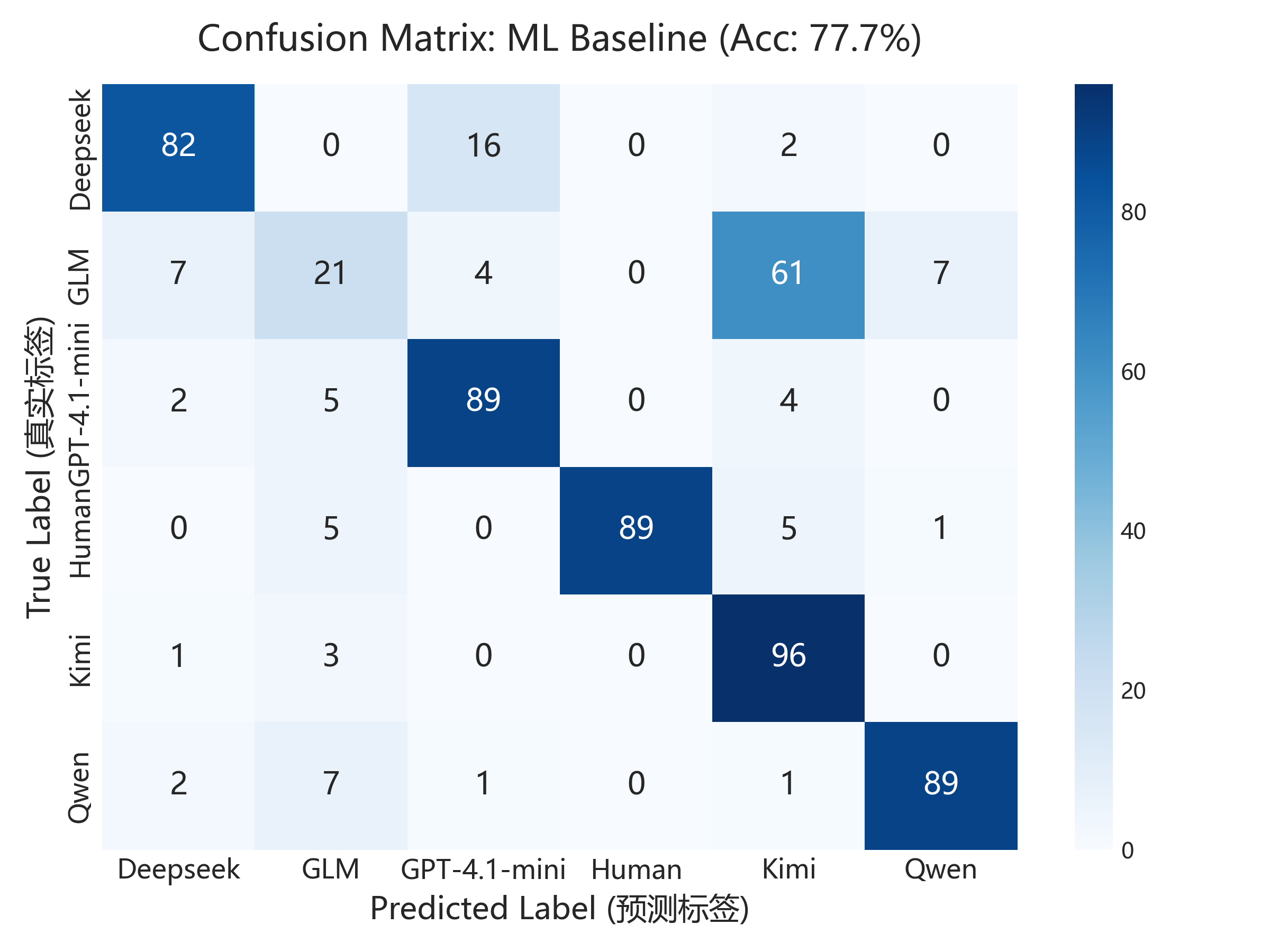
比较传统机器学习分类器与端到端模型,并做混淆矩阵和特征重要性分析。
泛化与对抗
测试跨题库、跨学科、跨语言表现,并观察防检测改写对分类器的影响。
关键图示