
MLfinal
This was my final project for Selected Topics in Deep Learning Theory. In the updated report, I frame the work as a reproducible study of delayed generalization on small algorithmic datasets: not a claim that I have explained grokking completely, but a compact place to watch memorization and rule learning compete.
I keep the experiment code and report material in GitHub / wjjpku/ML-final.
Course project framing
The report is titled Grokking on Small Algorithmic Datasets: A Reproducible Study of Delayed Generalization. I start from the classic modular-addition task with prime modulus 97, then use the same codebase to organize related tasks that still have an exact algebraic answer.
Every example is represented as a short sequence. For the binary modular tasks, the model sees operands, an operation token, an equality token, and then must predict only the final answer token. I like this setup because it removes most of the noise around language data. The model is not being rewarded for fluent text; it is being asked whether it can infer a rule from a partial operation table.
What the harness supports
The updated paper makes the project less like a single-plot reproduction and more like an experiment harness. The data layer supports modular arithmetic, polynomial modular operations, symmetric-group operations in S5, and K-ary modular summation. These tasks share the same sequence-prediction interface but vary in algebraic structure and combinatorial size.
The model layer also stays deliberately comparable. I use a small decoder-only Transformer as the main model, then run MLP, LSTM, and GRU baselines through the same training loop. That comparison matters because I do not want to describe grokking as a mysterious property of attention alone. In this project, delayed generalization is better understood as a property of overparameterized models learning finite algorithmic tables under optimization and regularization.
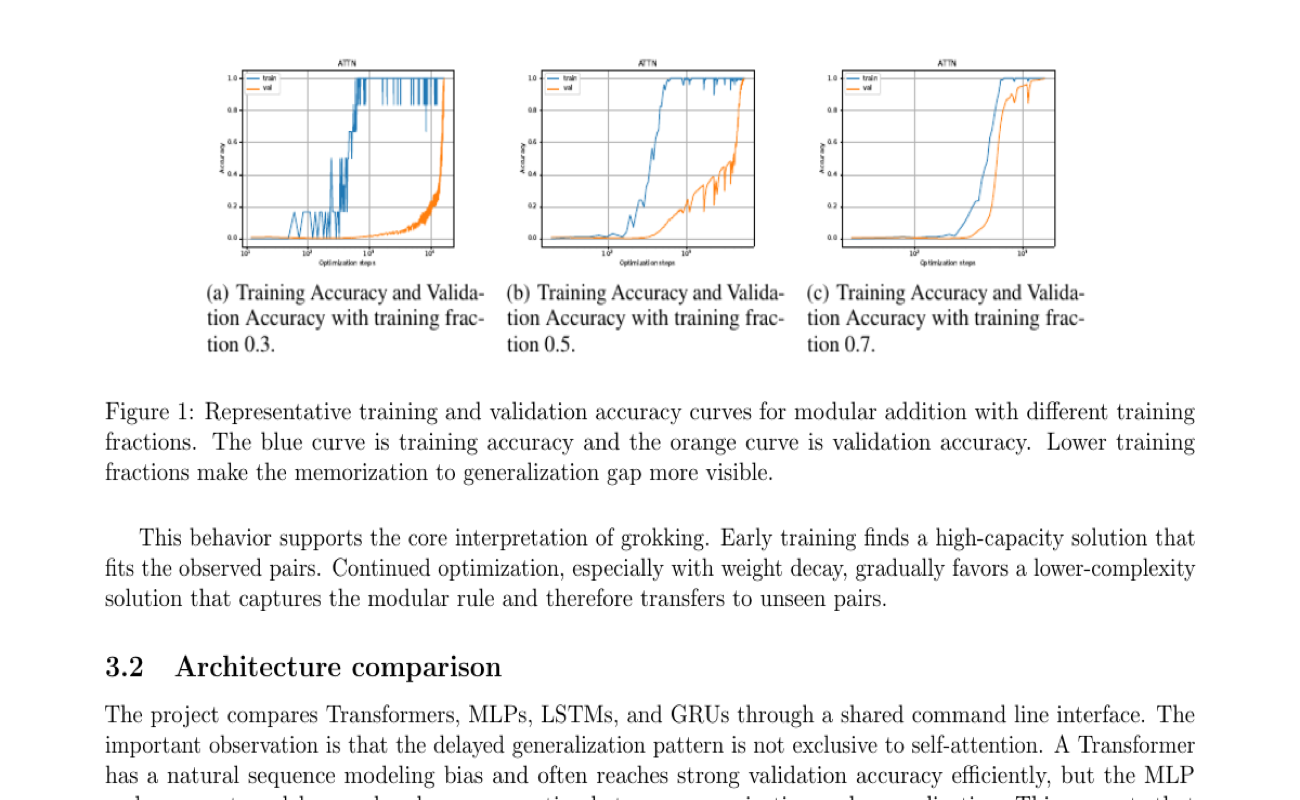
What the experiments show
The clearest pattern is the gap between training accuracy and validation accuracy. With sparse enough training data, the model can learn the observed table long before it learns a rule that transfers to held-out pairs. Lower training fractions make that gap more visible, while larger fractions blur it because more of the operation table is directly covered.
Optimizer and regularization choices change the time scale. AdamW is the natural default in the report because decoupled weight decay pushes against large memorizing solutions. Dropout and noise are useful controls, but they can also slow the transition if they disturb the path too much. The point is not merely to train longer; it is to train under biases that eventually make the compact rule-based solution more attractive.
The task extensions help me keep the explanation honest. Modular division asks the model to learn inverse structure. Polynomial modular tasks introduce higher-order interactions. S5 operations replace residues with permutations. K-ary summation increases sequence length and makes the full input space grow as (p^K). Those extensions do not prove a universal theory, but they make the codebase a useful base for testing which parts of the phenomenon survive beyond the simplest addition table.
Explanation I trust
The explanation I trust is a two-solution story. One solution memorizes enough of the finite table to do well on the training split. Another solution represents the underlying algebraic rule and therefore transfers. Early training can find the first solution quickly; continued optimization with regularization can later favor the second.
For modular addition, commutativity is an extra warning sign. If a train-validation split leaks too many commuted pairs, a model may improve validation accuracy by learning symmetry before it has learned the full modular rule. That made me more careful about how I interpret a grokking curve: the split itself can make the transition look cleaner or messier.
Reproducibility boundary
The repository is designed so that I can rerun the same logic across operations, architectures, optimizers, and training fractions. The report includes quick smoke tests, longer sparse-data runs, and architecture comparisons, but I treat those as course-project evidence rather than a finished theory of grokking.
The useful habit I got from this project is patience with dynamics. Training accuracy is only the first visible layer. The real question is what kind of internal solution the model is moving toward after it already knows the training set.
